英文原文
Consider all the leaves of a binary tree, from left to right order, the values of those leaves form a leaf value sequence.
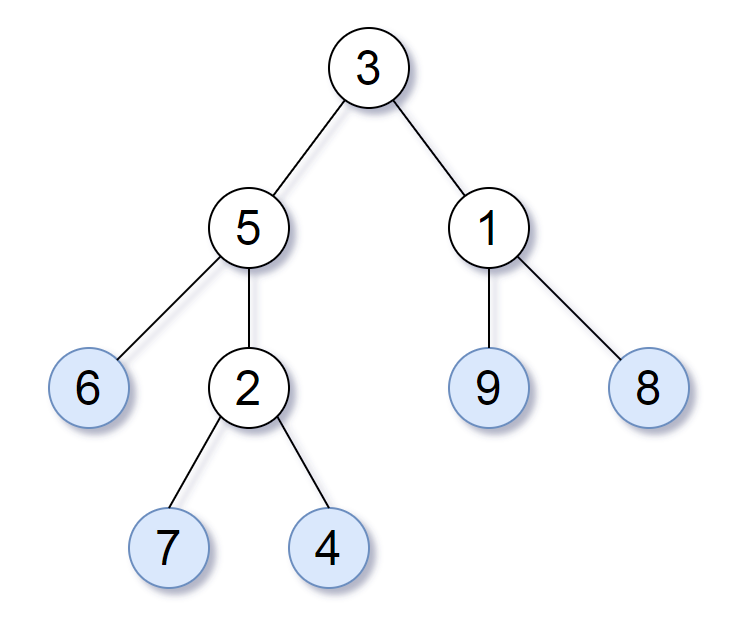
For example, in the given tree above, the leaf value sequence is (6, 7, 4, 9, 8).
Two binary trees are considered leaf-similar if their leaf value sequence is the same.
Return true if and only if the two given trees with head nodes root1 and root2 are leaf-similar.
Example 1:
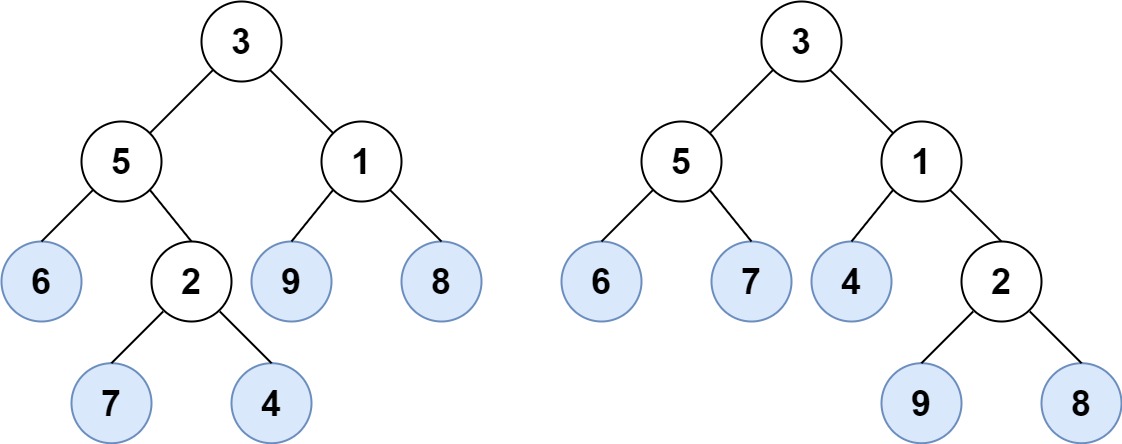
Input: root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8] Output: true
Example 2:
Input: root1 = [1], root2 = [1] Output: true
Example 3:
Input: root1 = [1], root2 = [2] Output: false
Example 4:
Input: root1 = [1,2], root2 = [2,2] Output: true
Example 5:
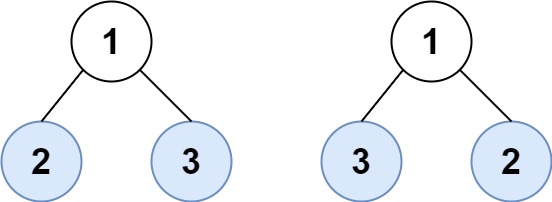
Input: root1 = [1,2,3], root2 = [1,3,2] Output: false
Constraints:
- The number of nodes in each tree will be in the range
[1, 200]. - Both of the given trees will have values in the range
[0, 200].
中文题目
请考虑一棵二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个 叶值序列 。
举个例子,如上图所示,给定一棵叶值序列为 (6, 7, 4, 9, 8) 的树。
如果有两棵二叉树的叶值序列是相同,那么我们就认为它们是 叶相似 的。
如果给定的两个根结点分别为 root1 和 root2 的树是叶相似的,则返回 true;否则返回 false 。
示例 1:
输入:root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8] 输出:true
示例 2:
输入:root1 = [1], root2 = [1] 输出:true
示例 3:
输入:root1 = [1], root2 = [2] 输出:false
示例 4:
输入:root1 = [1,2], root2 = [2,2] 输出:true
示例 5:
输入:root1 = [1,2,3], root2 = [1,3,2] 输出:false
提示:
- 给定的两棵树可能会有
1到200个结点。 - 给定的两棵树上的值介于
0到200之间。
通过代码
高赞题解
小明的第一感
**深搜(法一)**:
小明的妈妈昨天很开心,于是又给了他一个新的问题,“找不同”。对于两颗🌳,小明需要找到其对于的叶子节点的不同,如果两颗🌳的叶子节点的值是相同的,那么告诉妈妈它们一样$(返回true)$, 反之则告诉妈妈它们不一样$(返回false)$。
对于早已经会深搜的小明感觉智商受到了侮辱。于是他脑子里啪啪就想出了深搜的法子。他先拿了第一张纸(vector)对树进行了完全的遍历并储存了下 “树一” 的所有叶子节点的值,然后又拿了一张纸(vector)对树进行完全的遍历储存下了 “树二” 的所有叶子节点的值。然后进行了比对,并将结果告诉了妈妈。
class Solution {
public:
bool leafSimilar(TreeNode* root1, TreeNode* root2) {
vector<int> v1, v2;
dfs(root1, v1);
dfs(root2, v2);
return v1 == v2;
}
void dfs(TreeNode* root, vector<int>& vec)
{
if(!root->left && !root->right)
{
vec.push_back(root->val);
return;
}
if(root->left) dfs(root->left, vec);
if(root->right) dfs(root->right, vec);
}
};时间复杂度: $O(N1+N2)$,其中 $N1$ 与 $N2$为树的节点数量。
空间复杂度:储存叶子节点需要的空间为 $O(L1+L2)$,其中 $L1$ 与 $L2$为叶子的节点数量,递归的空间取决于树的高度 $O(h)$。
小明发现问题
同步遍历法(法二):
小明开心告诉妈妈答案后准备去找小红玩耍,然而他发现小红早已经等待了他半天。于是晚上回家后小明想有没有办法能提高今天对🌳找不同的速度!他发现了一个问题:尽管对于两棵树的第一个叶子节点不相同,他还是遍历了其所有的叶子节点**。问题出在哪?因为他先遍历一棵树,在遍历了第一棵🌳后他并不知道第二个🌳叶子节点的值,因此他还要继续重复遍历的操作。于是他想同时逐个比较两棵树的叶子节点,一但发现不同,立刻返回$false$。
这样子会有一个问题,同时观察两颗树他在观察一棵树回到另一颗树继续观察下一个叶子节点时不知从何开始。因此他还是需要辅助记录的小纸(stack)。然而这一次他记录的是下一个搜索的起始位置。
小明的同步遍历算法
- 使用两个栈分别记录两棵树其下一次出发搜寻叶子节点的起始点.
- 只要有任意一个栈为空,说明其树以经遍历完毕。这里有两种情况:
- 两个栈都空了,并且叶子节点都相等,因此返回true
- 只有一颗树空了,证明另一棵树一定还有别的叶子节点, 因此返回false
- 分别取出两个栈中两颗树出发搜寻叶子节点的起始点,并出发找到其对于的叶子节点。
- 左孩子不为空时,如果右孩子也不为空,则将其推入栈作为下次的起始点。然后继续往左搜寻叶子节点。
- 左孩子为空时,那么右孩子一定不为空,则出发往右孩子寻找第一个叶子节点。
- 当两棵树分别都找到叶子节点后,比较它们的值是否相等,如果不相等则返回$false$, 相等则继续找下一个叶子节点。
小明的作图笔记
发现问题的地方:



class Solution {
public:
bool leafSimilar(TreeNode* root1, TreeNode* root2) {
stack<TreeNode*> s1, s2;
s1.push(root1), s2.push(root2);
while(!s1.empty() && !s2.empty())
{
TreeNode* node1 = s1.top(); s1.pop();
TreeNode* node2 = s2.top(); s2.pop();
while(node1->left || node1->right)
{
if(node1->left)
{
if(node1->right) s1.push(node1->right);
node1 = node1->left;
}
else
node1 = node1->right;
}
//同样的操作对树2进行一遍
while(node2->left || node2->right)
{
if(node2->left)
{
if(node2->right) s2.push(node2->right);
node2 = node2->left;
}
else
node2 = node2->right;
}
//此时node1与node2分别指向树1与树2的叶子节点
if(node1->val != node2->val) return false;
}
//到此两种情况:
//1. 两个栈都空了,并且叶子节点都相等,因此返回true
//2. 只有一颗树空了,证明另一棵树一定还有别的叶子节点, 返回false;
return s1.empty() && s2.empty();
}
};时间复杂度:最坏情况也需要遍历所有节点,因此为 $O(N1+N2)$,其中 $N1$ 与 $N2$为树的节点数量
空间复杂度: 栈的空间取决于树的深度,因此为 $O(h)$。
虽然小明很厉害,但是我偷他的笔记也很累的,所以各位给个👍吧!
统计信息
| 通过次数 | 提交次数 | AC比率 |
|---|---|---|
| 61768 | 94744 | 65.2% |
提交历史
| 提交时间 | 提交结果 | 执行时间 | 内存消耗 | 语言 |
|---|



