原文链接: https://leetcode-cn.com/problems/delete-duplicate-folders-in-system
英文原文
Due to a bug, there are many duplicate folders in a file system. You are given a 2D array paths, where paths[i] is an array representing an absolute path to the ith folder in the file system.
- For example,
["one", "two", "three"]represents the path"/one/two/three".
Two folders (not necessarily on the same level) are identical if they contain the same non-empty set of identical subfolders and underlying subfolder structure. The folders do not need to be at the root level to be identical. If two or more folders are identical, then mark the folders as well as all their subfolders.
- For example, folders
"/a"and"/b"in the file structure below are identical. They (as well as their subfolders) should all be marked:<ul> <li><code>/a</code></li> <li><code>/a/x</code></li> <li><code>/a/x/y</code></li> <li><code>/a/z</code></li> <li><code>/b</code></li> <li><code>/b/x</code></li> <li><code>/b/x/y</code></li> <li><code>/b/z</code></li> </ul> </li> <li>However, if the file structure also included the path <code>"/b/w"</code>, then the folders <code>"/a"</code> and <code>"/b"</code> would not be identical. Note that <code>"/a/x"</code> and <code>"/b/x"</code> would still be considered identical even with the added folder.</li>
Once all the identical folders and their subfolders have been marked, the file system will delete all of them. The file system only runs the deletion once, so any folders that become identical after the initial deletion are not deleted.
Return the 2D array ans containing the paths of the remaining folders after deleting all the marked folders. The paths may be returned in any order.
Example 1:
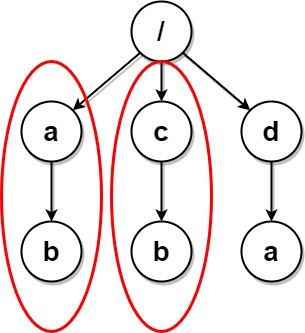
Input: paths = [["a"],["c"],["d"],["a","b"],["c","b"],["d","a"]] Output: [["d"],["d","a"]] Explanation: The file structure is as shown. Folders "/a" and "/c" (and their subfolders) are marked for deletion because they both contain an empty folder named "b".
Example 2:
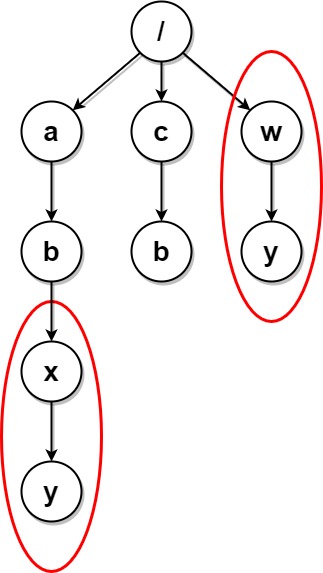
Input: paths = [["a"],["c"],["a","b"],["c","b"],["a","b","x"],["a","b","x","y"],["w"],["w","y"]] Output: [["c"],["c","b"],["a"],["a","b"]] Explanation: The file structure is as shown. Folders "/a/b/x" and "/w" (and their subfolders) are marked for deletion because they both contain an empty folder named "y". Note that folders "/a" and "/c" are identical after the deletion, but they are not deleted because they were not marked beforehand.
Example 3:
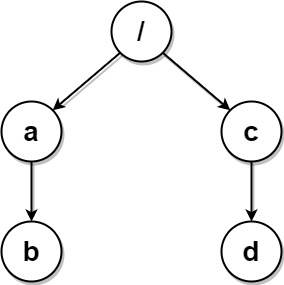
Input: paths = [["a","b"],["c","d"],["c"],["a"]] Output: [["c"],["c","d"],["a"],["a","b"]] Explanation: All folders are unique in the file system. Note that the returned array can be in a different order as the order does not matter.
Example 4:
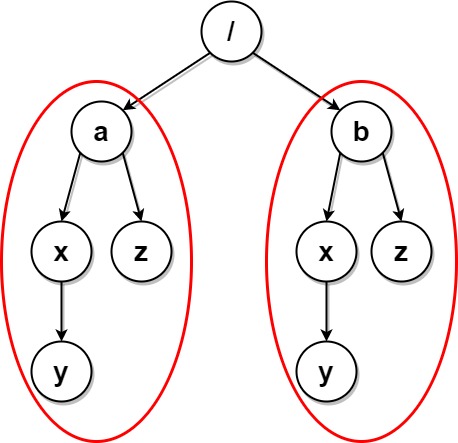
Input: paths = [["a"],["a","x"],["a","x","y"],["a","z"],["b"],["b","x"],["b","x","y"],["b","z"]] Output: [] Explanation: The file structure is as shown. Folders "/a/x" and "/b/x" (and their subfolders) are marked for deletion because they both contain an empty folder named "y". Folders "/a" and "/b" (and their subfolders) are marked for deletion because they both contain an empty folder "z" and the folder "x" described above.
Example 5:
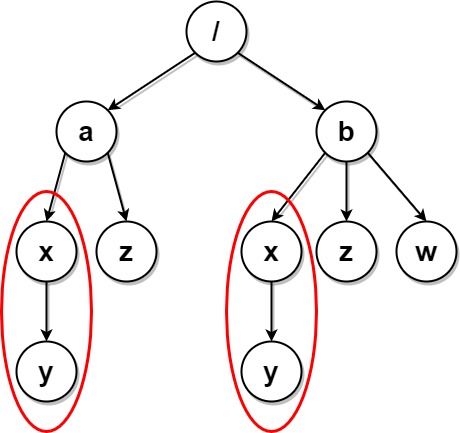
Input: paths = [["a"],["a","x"],["a","x","y"],["a","z"],["b"],["b","x"],["b","x","y"],["b","z"],["b","w"]] Output: [["b"],["b","w"],["b","z"],["a"],["a","z"]] Explanation: This has the same structure as the previous example, except with the added "/b/w". Folders "/a/x" and "/b/x" are still marked, but "/a" and "/b" are no longer marked because "/b" has the empty folder named "w" and "/a" does not. Note that "/a/z" and "/b/z" are not marked because the set of identical subfolders must be non-empty, but these folders are empty.
Constraints:
1 <= paths.length <= 2 * 1041 <= paths[i].length <= 5001 <= paths[i][j].length <= 101 <= sum(paths[i][j].length) <= 2 * 105path[i][j]consists of lowercase English letters.- No two paths lead to the same folder.
- For any folder not at the root level, its parent folder will also be in the input.
中文题目
由于一个漏洞,文件系统中存在许多重复文件夹。给你一个二维数组 paths,其中 paths[i] 是一个表示文件系统中第 i 个文件夹的绝对路径的数组。
- 例如,
["one", "two", "three"]表示路径"/one/two/three"。
如果两个文件夹(不需要在同一层级)包含 非空且相同的 子文件夹 集合 并具有相同的子文件夹结构,则认为这两个文件夹是相同文件夹。相同文件夹的根层级 不 需要相同。如果存在两个(或两个以上)相同 文件夹,则需要将这些文件夹和所有它们的子文件夹 标记 为待删除。
- 例如,下面文件结构中的文件夹
"/a"和"/b"相同。它们(以及它们的子文件夹)应该被 全部 标记为待删除:<ul> <li><code>/a</code></li> <li><code>/a/x</code></li> <li><code>/a/x/y</code></li> <li><code>/a/z</code></li> <li><code>/b</code></li> <li><code>/b/x</code></li> <li><code>/b/x/y</code></li> <li><code>/b/z</code></li> </ul> </li> <li>然而,如果文件结构中还包含路径 <code>"/b/w"</code> ,那么文件夹 <code>"/a"</code> 和 <code>"/b"</code> 就不相同。注意,即便添加了新的文件夹 <code>"/b/w"</code> ,仍然认为 <code>"/a/x"</code> 和 <code>"/b/x"</code> 相同。</li>
一旦所有的相同文件夹和它们的子文件夹都被标记为待删除,文件系统将会 删除 所有上述文件夹。文件系统只会执行一次删除操作。执行完这一次删除操作后,不会删除新出现的相同文件夹。
返回二维数组 ans ,该数组包含删除所有标记文件夹之后剩余文件夹的路径。路径可以按 任意顺序 返回。
示例 1:
输入:paths = [["a"],["c"],["d"],["a","b"],["c","b"],["d","a"]] 输出:[["d"],["d","a"]] 解释:文件结构如上所示。 文件夹 "/a" 和 "/c"(以及它们的子文件夹)都会被标记为待删除,因为它们都包含名为 "b" 的空文件夹。
示例 2:
输入:paths = [["a"],["c"],["a","b"],["c","b"],["a","b","x"],["a","b","x","y"],["w"],["w","y"]] 输出:[["c"],["c","b"],["a"],["a","b"]] 解释:文件结构如上所示。 文件夹 "/a/b/x" 和 "/w"(以及它们的子文件夹)都会被标记为待删除,因为它们都包含名为 "y" 的空文件夹。 注意,文件夹 "/a" 和 "/c" 在删除后变为相同文件夹,但这两个文件夹不会被删除,因为删除只会进行一次,且它们没有在删除前被标记。
示例 3:
输入:paths = [["a","b"],["c","d"],["c"],["a"]] 输出:[["c"],["c","d"],["a"],["a","b"]] 解释:文件系统中所有文件夹互不相同。 注意,返回的数组可以按不同顺序返回文件夹路径,因为题目对顺序没有要求。
示例 4:
输入:paths = [["a"],["a","x"],["a","x","y"],["a","z"],["b"],["b","x"],["b","x","y"],["b","z"]] 输出:[] 解释:文件结构如上所示。 文件夹 "/a/x" 和 "/b/x"(以及它们的子文件夹)都会被标记为待删除,因为它们都包含名为 "y" 的空文件夹。 文件夹 "/a" 和 "/b"(以及它们的子文件夹)都会被标记为待删除,因为它们都包含一个名为 "z" 的空文件夹以及上面提到的文件夹 "x" 。
示例 5:
输入:paths = [["a"],["a","x"],["a","x","y"],["a","z"],["b"],["b","x"],["b","x","y"],["b","z"],["b","w"]] 输出:[["b"],["b","w"],["b","z"],["a"],["a","z"]] 解释:本例与上例的结构基本相同,除了新增 "/b/w" 文件夹。 文件夹 "/a/x" 和 "/b/x" 仍然会被标记,但 "/a" 和 "/b" 不再被标记,因为 "/b" 中有名为 "w" 的空文件夹而 "/a" 没有。 注意,"/a/z" 和 "/b/z" 不会被标记,因为相同子文件夹的集合必须是非空集合,但这两个文件夹都是空的。
提示:
1 <= paths.length <= 2 * 1041 <= paths[i].length <= 5001 <= paths[i][j].length <= 101 <= sum(paths[i][j].length) <= 2 * 105path[i][j]由小写英文字母组成- 不会存在两个路径都指向同一个文件夹的情况
- 对于不在根层级的任意文件夹,其父文件夹也会包含在输入中
通过代码
高赞题解
我们用一颗字典树去表示整个文件系统,然后 DFS 这颗字典树,并用括号表达式按字典序拼接所有子树。
以示例 $4$ 为例,文件夹 $\texttt{a}$ 的子树的括号表达式为 $\texttt{(x(y))(z)}$。
 {:width=300}
{:width=300}
这一表达方式包含了子树的节点名称和父子关系,因此可用于判断两个文件夹是否为相同文件夹。
代码实现时,可以用一个哈希表去存储括号表达式及其对应的文件夹节点列表。在 DFS 结束后,遍历哈希表,若一个括号表达式对应的节点个数大于 $1$,则将该括号表达式对应的所有节点标记为待删除。然后再次 DFS 这颗字典树,仅访问未被删除的节点,并将路径记录到答案中。
type folder struct {
son map[string]*folder
val string // 文件夹名称
del bool // 删除标记
}
func deleteDuplicateFolder(paths [][]string) (ans [][]string) {
root := &folder{}
for _, path := range paths {
// 将 path 加入字典树
f := root
for _, s := range path {
if f.son == nil {
f.son = map[string]*folder{}
}
if f.son[s] == nil {
f.son[s] = &folder{}
}
f = f.son[s]
f.val = s
}
}
folders := map[string][]*folder{} // 存储括号表达式及其对应的文件夹节点列表
var dfs func(*folder) string
dfs = func(f *folder) string {
if f.son == nil {
return "(" + f.val + ")"
}
expr := make([]string, 0, len(f.son))
for _, son := range f.son {
expr = append(expr, dfs(son))
}
sort.Strings(expr)
subTreeExpr := strings.Join(expr, "") // 按字典序拼接所有子树
folders[subTreeExpr] = append(folders[subTreeExpr], f)
return "(" + f.val + subTreeExpr + ")"
}
dfs(root)
for _, fs := range folders {
if len(fs) > 1 { // 将括号表达式对应的节点个数大于 1 的节点全部删除
for _, f := range fs {
f.del = true
}
}
}
// 再次 DFS 这颗字典树,仅访问未被删除的节点,并将路径记录到答案中
path := []string{}
var dfs2 func(*folder)
dfs2 = func(f *folder) {
if f.del {
return
}
path = append(path, f.val)
ans = append(ans, append([]string(nil), path...))
for _, son := range f.son {
dfs2(son)
}
path = path[:len(path)-1]
}
for _, son := range root.son {
dfs2(son)
}
return
}统计信息
| 通过次数 | 提交次数 | AC比率 |
|---|---|---|
| 1018 | 1964 | 51.8% |
提交历史
| 提交时间 | 提交结果 | 执行时间 | 内存消耗 | 语言 |
|---|



