原文链接: https://leetcode-cn.com/problems/min-cost-to-connect-all-points
英文原文
You are given an array points representing integer coordinates of some points on a 2D-plane, where points[i] = [xi, yi].
The cost of connecting two points [xi, yi] and [xj, yj] is the manhattan distance between them: |xi - xj| + |yi - yj|, where |val| denotes the absolute value of val.
Return the minimum cost to make all points connected. All points are connected if there is exactly one simple path between any two points.
Example 1:
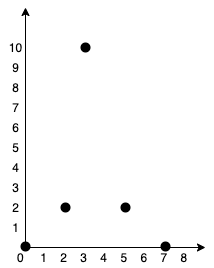
Input: points = [[0,0],[2,2],[3,10],[5,2],[7,0]] Output: 20 Explanation:We can connect the points as shown above to get the minimum cost of 20. Notice that there is a unique path between every pair of points.
Example 2:
Input: points = [[3,12],[-2,5],[-4,1]] Output: 18
Example 3:
Input: points = [[0,0],[1,1],[1,0],[-1,1]] Output: 4
Example 4:
Input: points = [[-1000000,-1000000],[1000000,1000000]] Output: 4000000
Example 5:
Input: points = [[0,0]] Output: 0
Constraints:
1 <= points.length <= 1000-106 <= xi, yi <= 106- All pairs
(xi, yi)are distinct.
中文题目
给你一个points 数组,表示 2D 平面上的一些点,其中 points[i] = [xi, yi] 。
连接点 [xi, yi] 和点 [xj, yj] 的费用为它们之间的 曼哈顿距离 :|xi - xj| + |yi - yj| ,其中 |val| 表示 val 的绝对值。
请你返回将所有点连接的最小总费用。只有任意两点之间 有且仅有 一条简单路径时,才认为所有点都已连接。
示例 1:
输入:points = [[0,0],[2,2],[3,10],[5,2],[7,0]] 输出:20 解释:
示例 2:
输入:points = [[3,12],[-2,5],[-4,1]] 输出:18
示例 3:
输入:points = [[0,0],[1,1],[1,0],[-1,1]] 输出:4
示例 4:
输入:points = [[-1000000,-1000000],[1000000,1000000]] 输出:4000000
示例 5:
输入:points = [[0,0]] 输出:0
提示:
1 <= points.length <= 1000-106 <= xi, yi <= 106- 所有点
(xi, yi)两两不同。
通过代码
高赞题解
连接所有点的最小费用,即最小生成树。
方法一: Prim算法
Part1. 解题思路
抽象(假想:假设存在,但不存在)出两个集合,集合V 和集合Vnew
集合
V保存未加入到最小生成树中的节点,最开始,所有的图节点都在集合V中集合
Vnew保存已经加入到最小生成树中的节点,如果一个节点加入到了最小生成树中,则将该节点加入到Vnew
说明: Vnew即最小生成树
Part2. 数据结构
Prim算法主要维护2个数组
lowcost 数组,表示V中的节点,保存V中每个节点离集合Vnew中所有节点的最短距离。如果节点已经加入到了集合Vnew中,则置为-1v 数组,表示V中节点的访问情况,最开始全部为0,表示未加入到Vnew中,若某节点加入到了集合Vnew中, 则将其置为-1
Part3. 步骤:
- 随机选择一个起点,将其加入到
Vnew中。同时,更新此时的数组lowcost和数组v- 遍历
lowcost,寻找lowcost中的最小值min(假设索引为j,j为Vnew中离V最近的点),将与索引j相对应的节点加入到Vnew中,并更新数组lowcost[j]和数组v[j]。- 找到lowcost中的最小值
j后,此时数组lowcost中的所有节点都要更新,因为此时集合Vnew中的节点增加了,集合V中的节点离Vnew的最近距离可能会缩短。- 根据新加入集合
Vnew中的节点j,更新所有的lowcost。- 重复步骤2,直到访问了所有的节点。
很明显,最后需要计算的最小生成树中所有节点之间的距离之和 便是每一步迭代时求得的lowcost中的最小值min的和
Part4. 举例:

Part5. 代码
class Solution {
public:
int prim(vector<vector<int> >& points, int start) {
int n = points.size();
int res = 0;
// 1. 将points转化成邻接矩阵, 这一步可有可无
vector<vector<int> > g(n, vector<int>(n));
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
int dist = abs(points[i][0] - points[j][0]) + abs(points[i][1] - points[j][1]);
g[i][j] = dist;
g[j][i] = dist;
}
}
// 记录V[i]到Vnew的最近距离
vector<int> lowcost(n, INT_MAX);
// 记录V[i]是否加入到了Vnew
vector<int> v(n, -1);
// 2. 先将start加入到Vnew
v[start] = 0;
for (int i = 0; i < n; i++) {
if (i == start) continue;
lowcost[i] = g[i][start];
}
// 3. 剩余n - 1个节点未加入到Vnew,遍历
for (int i = 1; i < n; i++) {
// 找出此时V中,离Vnew最近的点
int minIdx = -1;
int minVal = INT_MAX;
for (int j = 0; j < n; j++) {
if (v[j] == 0) continue;
if (lowcost[j] < minVal) {
minIdx = j;
minVal = lowcost[j];
}
}
// 将该点加入Vnew,更新lowcost和v
res += minVal;
v[minIdx] = 0;
lowcost[minIdx] = -1;
// 更新集合V中所有点的lowcost
for (int j = 0; j < n; j++) {
if (v[j] == -1 && g[j][minIdx] < lowcost[j]) {
lowcost[j] = g[j][minIdx];
}
}
}
return res;
}
int minCostConnectPoints(vector<vector<int>>& points) {
return prim(points, 0);
}
};Part6. 分析
时间复杂度:O(n * n)
空间复杂度:O(n * n)
需要注意的是,这里的
Prim算法是最常规的实现,每次寻找集合V中距离Vnew最近的点都有着O(n)的时间复杂度。
而在实际应用过程中,可以使用堆将算法的时间复杂度降低到O(m * log(n)),m是连通图的边数,本题中的m近似n的平方。Prim算法的时间复杂度与堆的实现方式有关,二叉堆或者斐波拉契堆,具体未深究。
补充一个Prim的堆优化
class Solution {
public:
int prim(vector<vector<int> >& points, int start) {
int n = points.size();
if (n == 0) return 0;
int res = 0;
// 将points转化成邻接表
vector<vector<int> > g(n);
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (i == j) continue;
g[i].push_back(j);
g[j].push_back(i);
}
}
// 记录V[i]到Vnew的最近距离
vector<int> lowcost(n, INT_MAX);
// 记录V[i]是否加入到了Vnew
vector<int> v(n, -1);
// 格式:<距离, 下标>
priority_queue<pair<int, int>, vector<pair<int, int> >, greater<> > pq;
pq.push(make_pair(0, start));
while (!pq.empty()) {
auto [dist, i] = pq.top();
pq.pop();
if (v[i] == 0) continue;
v[i] = 0;
res += dist;
for (int k = 0; k < g[i].size(); k++) {
int j = g[i][k];
int w = abs(points[i][0] - points[j][0]) + abs(points[i][1] - points[j][1]);
if (v[j] == -1 && lowcost[j] > w) {
lowcost[j] = w;
pq.push(make_pair(w, j));
}
}
}
return res;
}
int minCostConnectPoints(vector<vector<int>>& points) {
return prim(points, 0);
}
};方法二、Kruskal(并查集)
前言
如果您对并查集还不是太了解,可以看看我之前的题解【详解并查集】,里面有详细的解释和通用模板。
如果有任何问题,欢迎随时交流!
Part1. 解题思路
Kruskal算法与prim算法不同:
Prim算法是以顶点为基础(每次寻找离
Vnew最近的顶点);
而
Kruskal算法是以 边 为基础,每次从 边 集合中寻找最小的边(不管两个顶点属于V还是Vnew),然后判断该边的两个顶点是否同源(属于同一个连通分量)。
Kruskal需要对所有的边进行排序,然后从小到大,依次遍历每条边,同时判断每条边是否同源,如果同源,跳过;如果不同源,将两个连通分量合并,直到所有顶点属于同一个连通分量,算法结束。
看到这里,数据结构已经很明显了,没错,我们离不开并查集了。
Part2. 数据结构
因为算法要求我们对所有边进行排序,同时需要知道每条边的两个端点
所以可以建立一个结构体/类,保存以上三个属性<start,end,len>(这里称为点-边式)。
其中start和end分别为两个顶点, len为两顶点的权值,即两点之间的距离
struct VP {
int start; // 顶点1
int end; // 顶点2
int len; // 长度
};Part3. 步骤
- 初始化:将图(邻接矩阵或邻接表)转换成
点-边式,并对点-边式按边的长度进行排序。同时,初始化并查集(有关并查集,这里就不过多赘述,具体可以看我的题解【并查集详解】)。- 依次遍历所有的
点-边式,每次取最小值。- 作如下判断:如果该
点-边式的两个顶点同源,跳过;如果该点-边式的两个顶点不同源,则将这两个源(连通分量)合并- 重复步骤2,直到存在一个连通分量,包含了图中所有的节点
- 算法结束
Part4. 举例

Part5. 代码
class Djset {
public:
vector<int> parent; // 记录节点的根
vector<int> rank; // 记录根节点的深度(用于优化)
vector<int> size; // 记录每个连通分量的节点个数
vector<int> len; // 记录每个连通分量里的所有边长度
int num; // 记录节点个数
Djset(int n): parent(n), rank(n), len(n, 0), size(n, 1), num(n) {
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
int find(int x) {
// 压缩方式:直接指向根节点
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
return parent[x];
}
int merge(int x, int y, int length) {
int rootx = find(x);
int rooty = find(y);
if (rootx != rooty) {
if (rank[rootx] < rank[rooty]) {
swap(rootx, rooty);
}
parent[rooty] = rootx;
if (rank[rootx] == rank[rooty]) rank[rootx] += 1;
// rooty的父节点设置为rootx,同时将rooty的节点数和边长度累加到rootx,
size[rootx] += size[rooty];
len[rootx] += len[rooty] + length;
// 如果某个连通分量的节点数 包含了所有节点,直接返回边长度
if (size[rootx] == num) return len[rootx];
}
return -1;
}
};
struct Edge {
int start; // 顶点1
int end; // 顶点2
int len; // 长度
};
class Solution {
public:
int minCostConnectPoints(vector<vector<int>>& points) {
int res = 0;
int n = points.size();
Djset ds(n);
vector<Edge> edges;
// 建立点-边式数据结构
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
Edge edge = {i, j, abs(points[i][0] - points[j][0]) + abs(points[i][1] - points[j][1])};
edges.emplace_back(edge);
}
}
// 按边长度排序
sort(edges.begin(), edges.end(), [](const auto& a, const auto& b) {
return a.len < b.len;
});
// 连通分量合并
for (auto& e : edges) {
res = ds.merge(e.start, e.end, e.len);
if (res != -1) return res;
}
return 0;
}
};Part6. 分析
时间复杂度:O(m log(m) + m α(m) ), 排序带来了m log(m)的时间复杂度,并查集合并带来m α(m)的时间复杂度,m为索引对的数量,近似于n * n。
空间复杂度:O(n * n)
总结
Prim算法,该算法以顶点为单元,与图中边数无关,比较适合于稠密图
Kruskal算法,该算法以边为单元,时间主要取决于边数,比较适合于稀疏图
感谢您的观看,如有错误还请不吝指出!
统计信息
| 通过次数 | 提交次数 | AC比率 |
|---|---|---|
| 27486 | 41441 | 66.3% |
提交历史
| 提交时间 | 提交结果 | 执行时间 | 内存消耗 | 语言 |
|---|



