英文原文
Given a n * n matrix grid of 0's and 1's only. We want to represent the grid with a Quad-Tree.
Return the root of the Quad-Tree representing the grid.
Notice that you can assign the value of a node to True or False when isLeaf is False, and both are accepted in the answer.
A Quad-Tree is a tree data structure in which each internal node has exactly four children. Besides, each node has two attributes:
val: True if the node represents a grid of 1's or False if the node represents a grid of 0's.isLeaf: True if the node is leaf node on the tree or False if the node has the four children.
class Node {
public boolean val;
public boolean isLeaf;
public Node topLeft;
public Node topRight;
public Node bottomLeft;
public Node bottomRight;
}
We can construct a Quad-Tree from a two-dimensional area using the following steps:
- If the current grid has the same value (i.e all
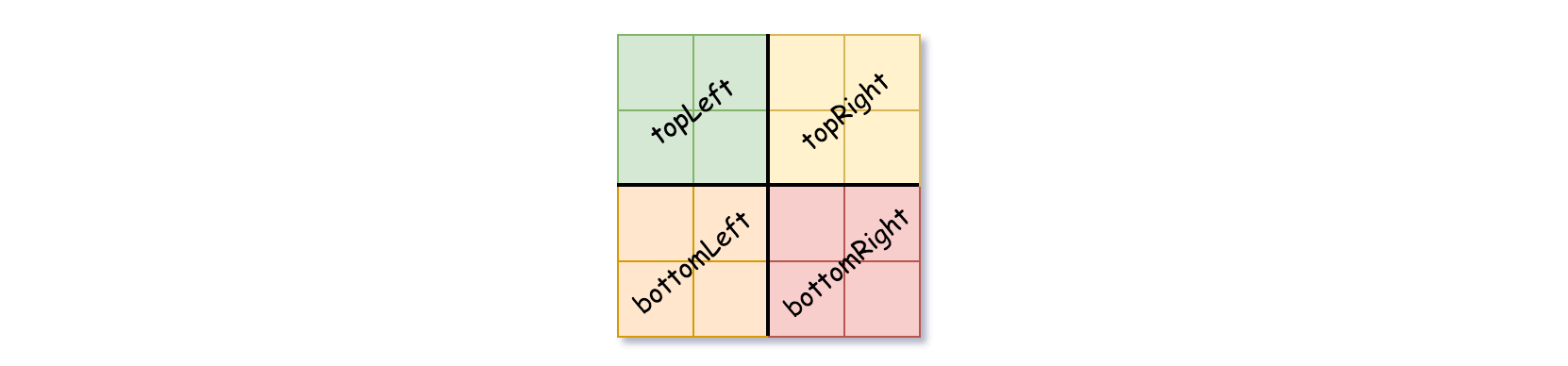
1'sor all0's) setisLeafTrue and setvalto the value of the grid and set the four children to Null and stop. - If the current grid has different values, set
isLeafto False and setvalto any value and divide the current grid into four sub-grids as shown in the photo. - Recurse for each of the children with the proper sub-grid.
If you want to know more about the Quad-Tree, you can refer to the wiki.
Quad-Tree format:
The output represents the serialized format of a Quad-Tree using level order traversal, where null signifies a path terminator where no node exists below.
It is very similar to the serialization of the binary tree. The only difference is that the node is represented as a list [isLeaf, val].
If the value of isLeaf or val is True we represent it as 1 in the list [isLeaf, val] and if the value of isLeaf or val is False we represent it as 0.
Example 1:

Input: grid = [[0,1],[1,0]] Output: [[0,1],[1,0],[1,1],[1,1],[1,0]] Explanation: The explanation of this example is shown below: Notice that 0 represnts False and 1 represents True in the photo representing the Quad-Tree.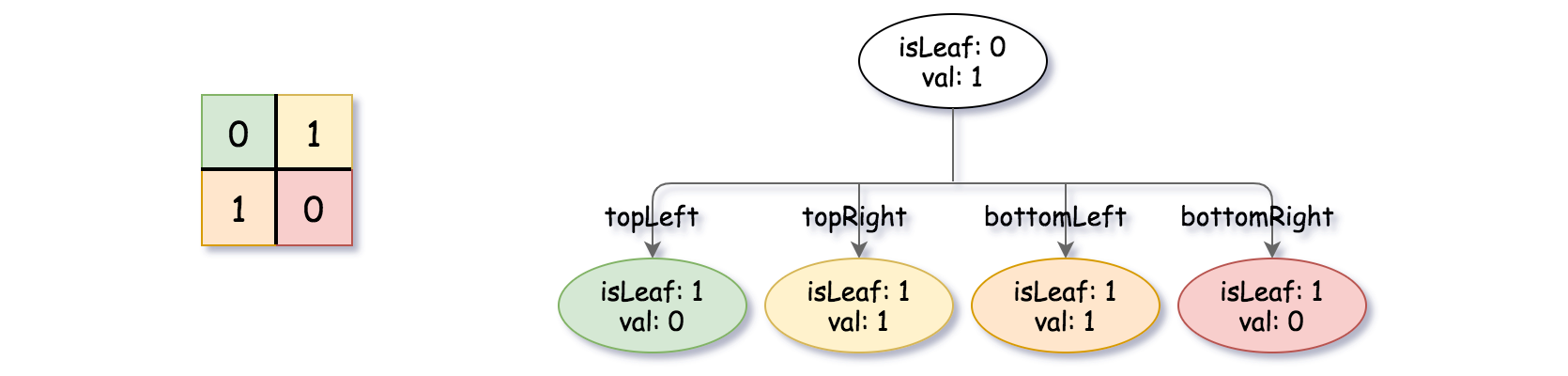
Example 2:
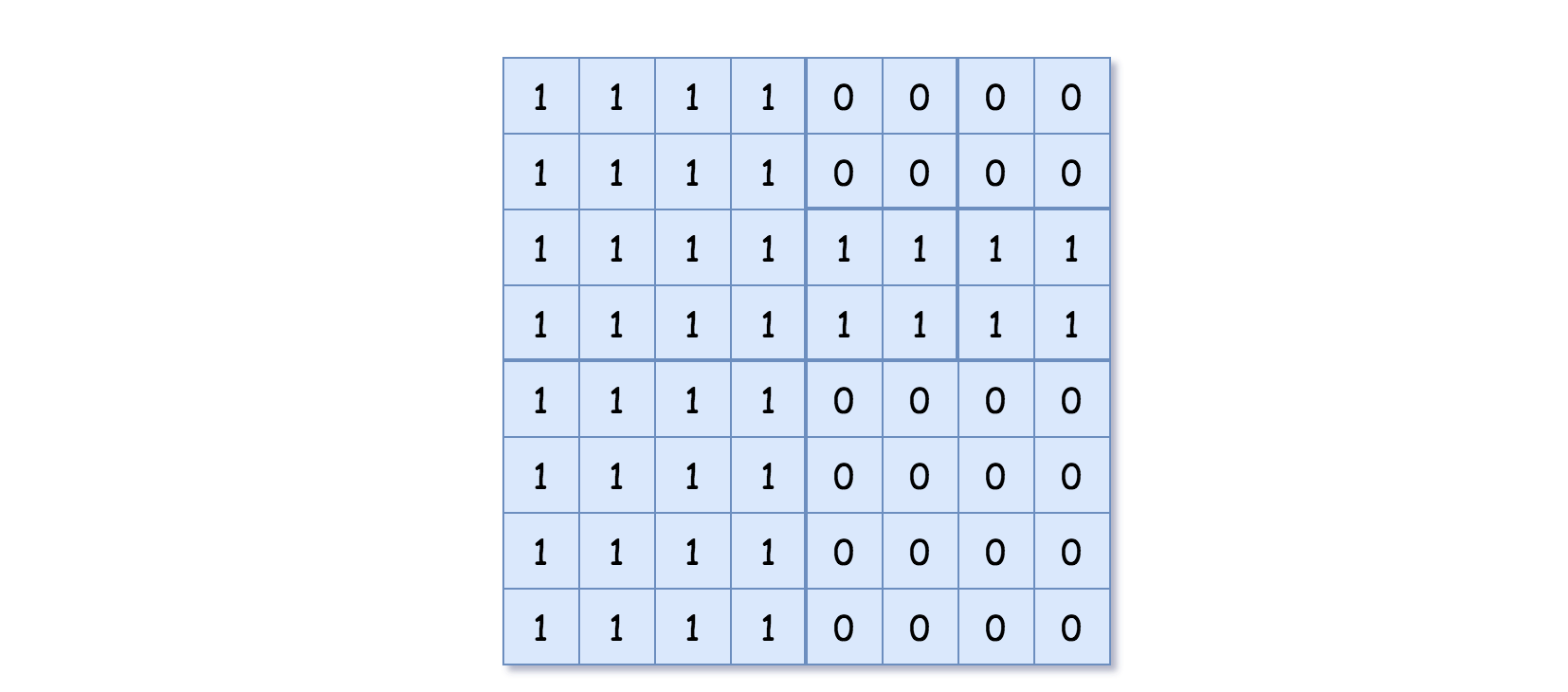
Input: grid = [[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,1,1,1,1],[1,1,1,1,1,1,1,1],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0]] Output: [[0,1],[1,1],[0,1],[1,1],[1,0],null,null,null,null,[1,0],[1,0],[1,1],[1,1]] Explanation: All values in the grid are not the same. We divide the grid into four sub-grids. The topLeft, bottomLeft and bottomRight each has the same value. The topRight have different values so we divide it into 4 sub-grids where each has the same value. Explanation is shown in the photo below: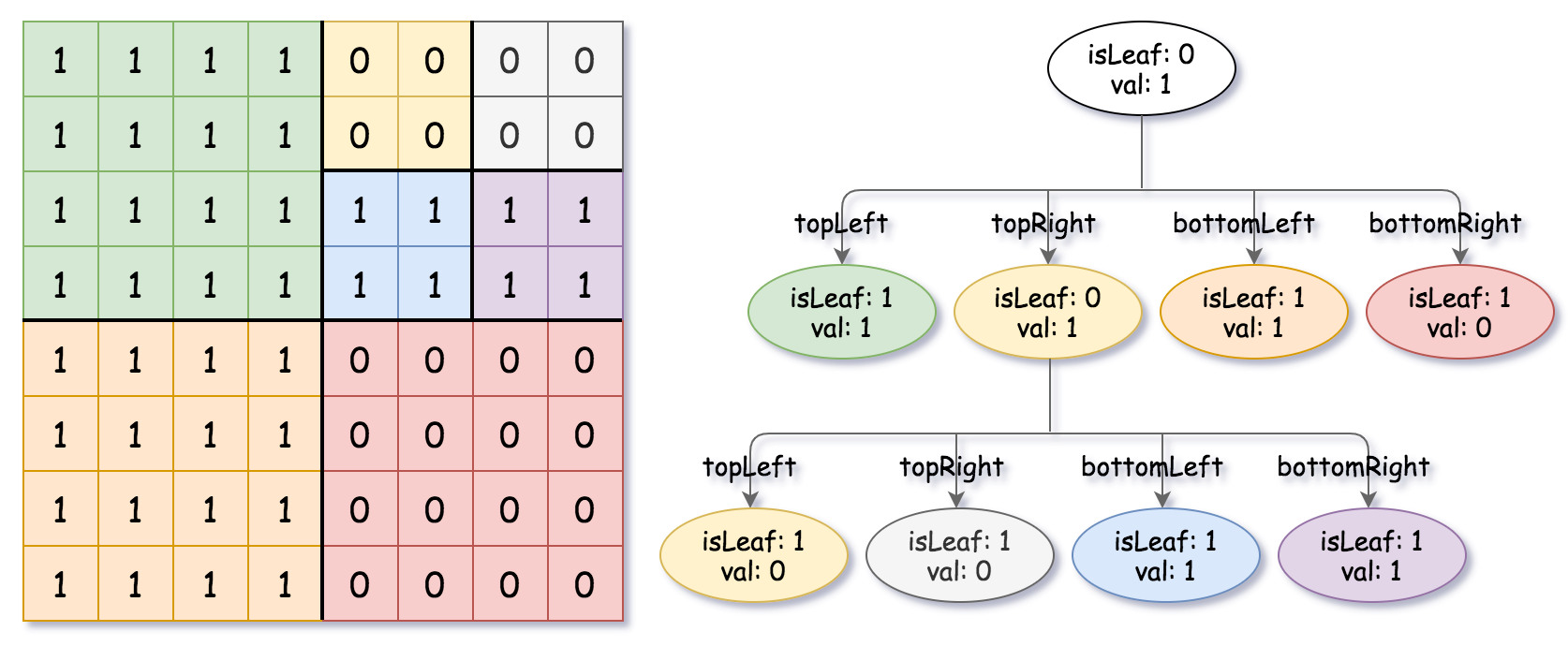
Example 3:
Input: grid = [[1,1],[1,1]] Output: [[1,1]]
Example 4:
Input: grid = [[0]] Output: [[1,0]]
Example 5:
Input: grid = [[1,1,0,0],[1,1,0,0],[0,0,1,1],[0,0,1,1]] Output: [[0,1],[1,1],[1,0],[1,0],[1,1]]
Constraints:
n == grid.length == grid[i].lengthn == 2^xwhere0 <= x <= 6
中文题目
给你一个 n * n 矩阵 grid ,矩阵由若干 0 和 1 组成。请你用四叉树表示该矩阵 grid 。
你需要返回能表示矩阵的 四叉树 的根结点。
注意,当 isLeaf 为 False 时,你可以把 True 或者 False 赋值给节点,两种值都会被判题机制 接受 。
四叉树数据结构中,每个内部节点只有四个子节点。此外,每个节点都有两个属性:
val:储存叶子结点所代表的区域的值。1 对应 True,0 对应 False;isLeaf: 当这个节点是一个叶子结点时为 True,如果它有 4 个子节点则为 False 。
class Node {
public boolean val;
public boolean isLeaf;
public Node topLeft;
public Node topRight;
public Node bottomLeft;
public Node bottomRight;
}
我们可以按以下步骤为二维区域构建四叉树:
- 如果当前网格的值相同(即,全为
0或者全为1),将isLeaf设为 True ,将val设为网格相应的值,并将四个子节点都设为 Null 然后停止。 - 如果当前网格的值不同,将
isLeaf设为 False, 将val设为任意值,然后如下图所示,将当前网格划分为四个子网格。 - 使用适当的子网格递归每个子节点。
如果你想了解更多关于四叉树的内容,可以参考 wiki 。
四叉树格式:
输出为使用层序遍历后四叉树的序列化形式,其中 null 表示路径终止符,其下面不存在节点。
它与二叉树的序列化非常相似。唯一的区别是节点以列表形式表示 [isLeaf, val] 。
如果 isLeaf 或者 val 的值为 True ,则表示它在列表 [isLeaf, val] 中的值为 1 ;如果 isLeaf 或者 val 的值为 False ,则表示值为 0 。
示例 1:
输入:grid = [[0,1],[1,0]] 输出:[[0,1],[1,0],[1,1],[1,1],[1,0]] 解释:此示例的解释如下: 请注意,在下面四叉树的图示中,0 表示 false,1 表示 True 。
示例 2:
输入:grid = [[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,1,1,1,1],[1,1,1,1,1,1,1,1],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0],[1,1,1,1,0,0,0,0]] 输出:[[0,1],[1,1],[0,1],[1,1],[1,0],null,null,null,null,[1,0],[1,0],[1,1],[1,1]] 解释:网格中的所有值都不相同。我们将网格划分为四个子网格。 topLeft,bottomLeft 和 bottomRight 均具有相同的值。 topRight 具有不同的值,因此我们将其再分为 4 个子网格,这样每个子网格都具有相同的值。 解释如下图所示:
示例 3:
输入:grid = [[1,1],[1,1]] 输出:[[1,1]]
示例 4:
输入:grid = [[0]] 输出:[[1,0]]
示例 5:
输入:grid = [[1,1,0,0],[1,1,0,0],[0,0,1,1],[0,0,1,1]] 输出:[[0,1],[1,1],[1,0],[1,0],[1,1]]
提示:
n == grid.length == grid[i].lengthn == 2^x其中0 <= x <= 6
通过代码
高赞题解

class Solution {
public:
/*
核心思路:
当前矩阵由三个参数确定:左上角元素的行号 row 列号 col,以及矩阵规模 N
判断当前矩阵是否为叶子节点,方法为比较左上角元素和其他元素的关系,
若出现不等则为非叶节点,需要继续划分,每个划分后的矩阵规模为 N/2 * N/2,
这 4 个矩阵递归地生成当前节点的 4 个子节点。
若元素全相等则返回一个叶子节点 (true, grid[row][col])。
**/
Node* helper(vector<vector<int>>& grid, int row, int col, int N) {
int first = grid[row][col];
Node *result = new Node();
bool isLeaf = true;
int m, n;
m = row+N;
n = col+N;
// 遍历比较每个元素与左上角元素的值
for (int i = row; i < m; ++i) {
for (int j = col; j < n; ++j)
if (grid[i][j] != first) {
isLeaf = false;
break;
}
if (!isLeaf) break;
}
if (isLeaf) {
result->val = first;
result->isLeaf = isLeaf;
} else {
// 存在不一样的元素,递归计算子节点,每个子矩阵的行列数减半
N /= 2;
result->isLeaf = isLeaf;
result->topLeft = helper(grid, row, col, N);
result->topRight = helper(grid, row, col+N, N);
result->bottomLeft = helper(grid, row+N, col, N);
result->bottomRight = helper(grid, row+N, col+N, N);
}
return result;
}
Node* construct(vector<vector<int>>& grid) {
int N = (int)grid.size();
if (N == 0) return NULL;
return helper(grid, 0, 0, N);
}
};统计信息
| 通过次数 | 提交次数 | AC比率 |
|---|---|---|
| 4366 | 7074 | 61.7% |
提交历史
| 提交时间 | 提交结果 | 执行时间 | 内存消耗 | 语言 |
|---|



